


¿Alguna vez te has preguntado cómo tu smartphone predice la siguiente palabra antes de que termines de escribir? A diferencia de los modelos tradicionales, que analizan datos de forma estática, la Red Neuronal Recurrente (RNN) actúa como el sistema de memoria de la inteligencia artificial. Su capacidad reside en procesar secuencias temporales, permitiendo que la máquina “recuerde” información previa para interpretar correctamente el presente.
Esta arquitectura no trata los datos como piezas aisladas, sino como un flujo continuo donde el orden es fundamental para el significado. Al integrar el contexto histórico en cada predicción, las RNN han transformado sectores como la traducción automática y el reconocimiento de voz. En este artículo, desglosaremos cómo esta tecnología permite a los modelos actuales razonar sobre el lenguaje y el tiempo, preparándote para profundizar en su funcionamiento técnico y aplicaciones prácticas.
En este post encontraras
¿Qué es una red neuronal recurrente?
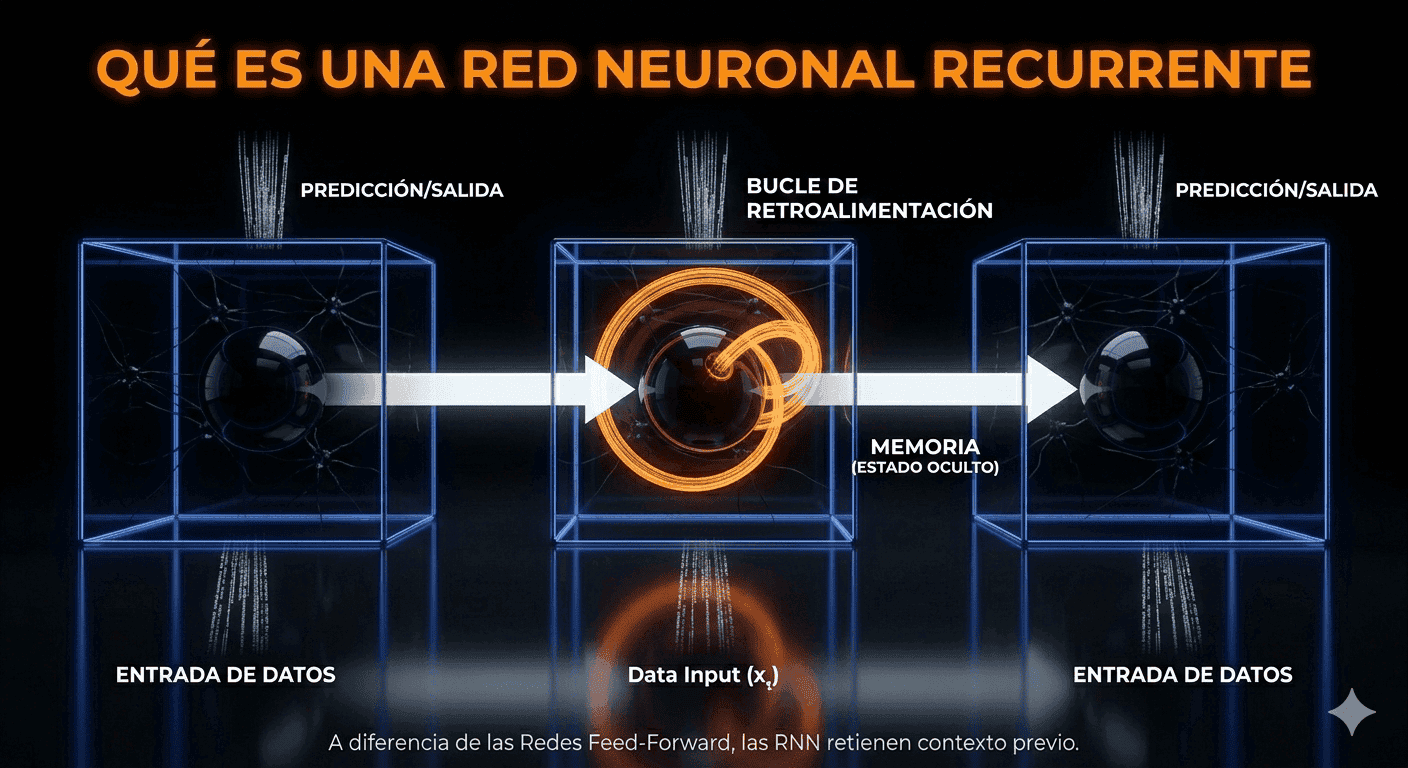
Para comprender realmente qué es una red neuronal recurrente, debemos visualizarla no como un proceso estático, sino como un sistema con memoria. Mientras que las redes neuronales convencionales tratan cada entrada de forma aislada, la RNN introduce la capacidad de persistencia, esencial para tareas donde el contexto temporal es el núcleo del problema.
La arquitectura del bucle de retroalimentación
La diferencia técnica fundamental radica en su bucle de retroalimentación. En una arquitectura estándar, la información fluye en una sola dirección: de la entrada a la salida. Sin embargo, en una red neuronal recurrente, la salida de un paso se convierte en parte de la entrada del siguiente. Este diseño permite que la red mantenga un estado oculto que actúa como un contenedor de información previa, permitiendo que el modelo “recuerde” datos analizados instantes antes.
RNN frente a redes feed-forward
Las redes feed-forward son excelentes para clasificar imágenes o datos donde el orden no altera el resultado final. No obstante, son incapaces de entender una oración o la fluctuación de un activo financiero porque carecen de visión histórica.
Las redes feed-forward procesan datos de manera independiente, sin conexión entre eventos pasados y futuros mientras que las redes neuronales recurrentes integran el contexto histórico, lo que las hace indispensables para el procesamiento de lenguaje natural y series temporales.
La metáfora de la memoria en los datos
Imagina leer un libro donde cada palabra se borra de tu memoria instantáneamente; no podrías entender ninguna frase compleja. La RNN soluciona esto al codificar la historia en sus pesos internos. Al procesar una secuencia, la red combina la entrada actual con el aprendizaje de los pasos anteriores, generando una predicción mucho más precisa. Es precisamente esta arquitectura la que permite que los sistemas modernos mantengan la coherencia en conversaciones largas o predicciones de texto en tiempo real.
¿Cómo funciona el procesamiento de secuencias en una red neuronal recurrente?
Para entender el aprendizaje profundo en tareas secuenciales, debemos analizar cómo las RNN procesan la información mediante iteración constante.
El estado oculto actúa como la memoria a corto plazo de la red. En cada paso, este integra la entrada actual y el estado anterior, permitiendo que la información fluya a través del tiempo y contextualice los datos basándose en el historial reciente.
Aunque operan cíclicamente, visualizamos a las RNN desenrollando el proceso: la red se replica por cada elemento de la secuencia manteniendo pesos compartidos. Estos parámetros garantizan un aprendizaje consistente, sin importar la posición del dato. Mediante la retropropagación a través del tiempo, la red ajusta sus pesos internos al comparar predicciones con la realidad, minimizando el error.
Así, la RNN refina su representación interna, filtrando información irrelevante y transformando datos crudos en una comprensión semántica profunda.
¿Cuál es el problema principal de las RNN?
A pesar de su capacidad revolucionaria para procesar secuencias, las redes neuronales recurrentes enfrentan limitaciones estructurales que complican su desempeño en tareas de alta complejidad. El reto fundamental no reside en la lógica de su diseño, sino en la optimización necesaria para que el modelo aprenda de manera efectiva cuando las secuencias se extienden demasiado en el tiempo.
El fenómeno del desvanecimiento del gradiente
El problema técnico más crítico es conocido como el desvanecimiento del gradiente o vanishing gradient. Durante el entrenamiento de redes neuronales mediante retropropagación, los gradientes —las señales matemáticas que dictan cómo deben ajustarse los pesos— se multiplican repetidamente a medida que la información retrocede en el tiempo. Cuando la secuencia es larga, estos valores se reducen exponencialmente hasta volverse insignificantes, dejando a la red incapaz de aprender de los errores cometidos al principio de la cadena.
Este fenómeno provoca que la memoria de la red se diluya, impidiendo que el modelo capture patrones relevantes que ocurrieron hace muchos pasos. En términos prácticos, es como intentar recordar el inicio de un párrafo largo después de haber leído varias páginas; la información se vuelve borrosa y pierde su peso original en la toma de decisiones final.
Dificultades con dependencias a largo plazo
Esta limitación genera una marcada dificultad para establecer dependencias a largo plazo. Aunque, en teoría, una RNN debería ser capaz de conectar el inicio de un documento con su conclusión, en la práctica el desvanecimiento del gradiente impide que los datos distantes ejerzan influencia sobre las predicciones actuales.
Para los investigadores, este es el principal obstáculo en la optimización de modelos avanzados. Si el gradiente desaparece, el modelo se estanca y pierde coherencia lógica, obligando a los ingenieros a buscar alternativas que permitan retener información crítica por mucho más tiempo sin corromper la señal de aprendizaje.

¿Qué es una red recurrente frente a una recursiva?
Es habitual encontrar confusión al comparar estas arquitecturas de deep learning, ya que ambos términos aluden a sistemas que procesan datos estructurados. Sin embargo, su comportamiento ante las topologías de red y la jerarquía de los datos es profundamente distinto.
Diferencias estructurales fundamentales
La red recurrente (RNN) es, por definición, una cadena lineal que procesa secuencias paso a paso en el tiempo, siguiendo el flujo de una línea temporal donde cada entrada depende de la anterior. Por el contrario, la red neuronal recursiva opera sobre estructuras de datos jerárquicas o en forma de árbol, aplicando pesos de manera reiterada sobre nodos que se conectan entre sí de forma compleja.
Aplicaciones y cuándo usar cada una
La elección entre ambas depende estrictamente de la naturaleza de los datos. Las RNN son imbatibles para series temporales y audio, donde el orden cronológico es sagrado.
Las redes recursivas, en cambio, se utilizan para comprender estructuras gramaticales complejas o relaciones jerárquicas en la organización de datos, donde la profundidad depende de la configuración de los elementos y no solo del paso del tiempo. Entender esta distinción es vital para optimizar el rendimiento en proyectos de inteligencia artificial avanzada.

¡QUE ESPERAS PARA SER PARTE DE NUESTRA COMUNIDAD!
Tipos de Red Neuronal Recurrente
La arquitectura original de las RNN ha evolucionado para superar las limitaciones de memoria que discutimos anteriormente. Hoy, los modelos de red neuronal se categorizan según su capacidad para gestionar flujos de datos complejos, dando lugar a variantes especializadas en el manejo de dependencias a largo plazo dentro de los diferentes tipos de RNN.
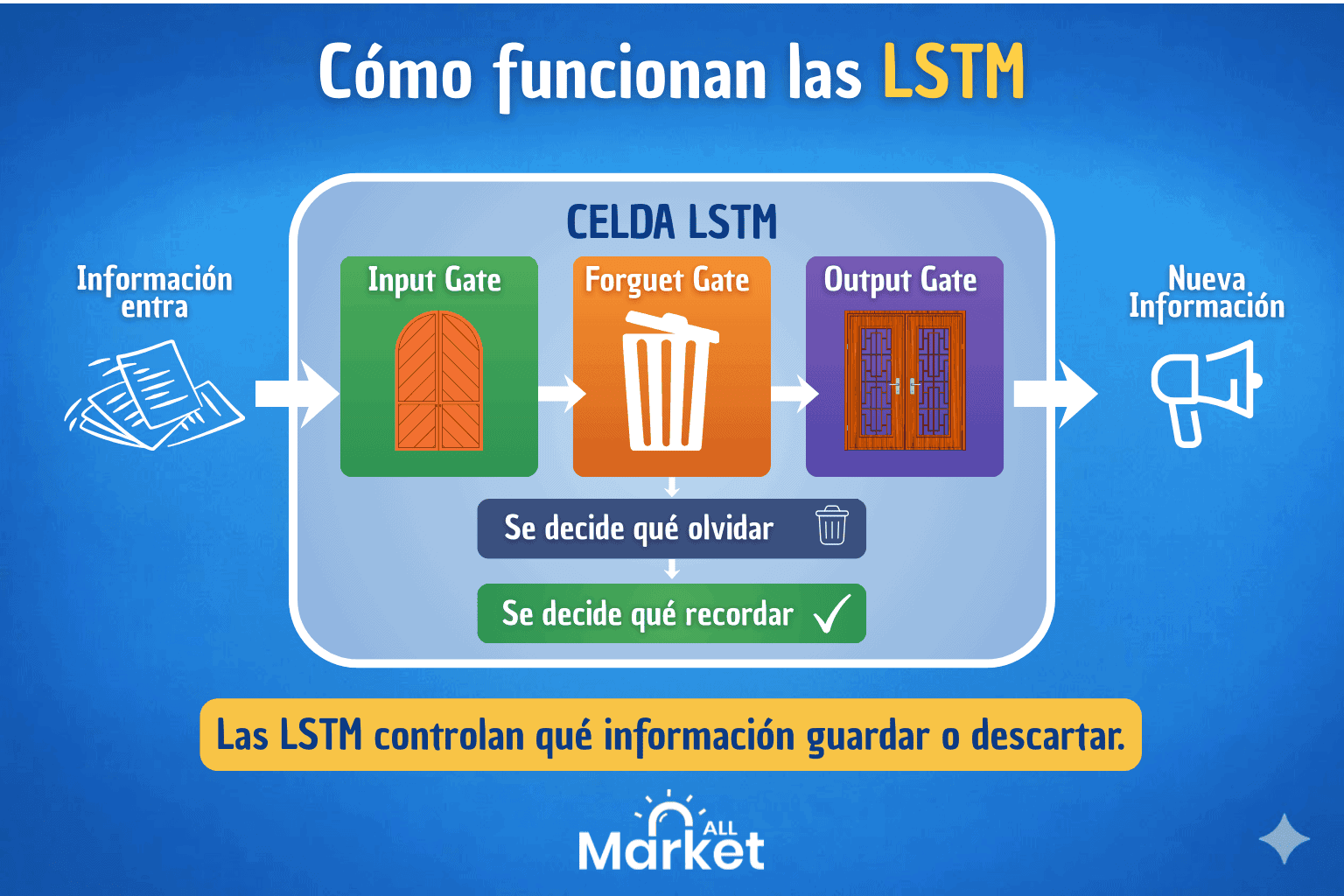
La evolución hacia LSTM
Las redes Long Short-Term Memory (LSTM) fueron diseñadas específicamente para resolver el problema del desvanecimiento del gradiente. A diferencia de la unidad básica, una celda LSTM incorpora una estructura de compuertas internas —entrada, salida y olvido— que decide qué información debe mantenerse en el estado oculto y qué debe ser descartada. Este control preciso permite a la red retener información durante secuencias mucho más extensas, siendo el estándar de oro en aplicaciones donde el contexto a largo plazo es indispensable.
La eficiencia de las GRU
Por su parte, las Gated Recurrent Unit (GRU) ofrecen una alternativa simplificada a las LSTM. Al fusionar la compuerta de olvido y de entrada en una única “compuerta de actualización”, las GRU logran un equilibrio eficiente entre rendimiento y costo computacional. Son ideales cuando se requiere una velocidad de entrenamiento superior sin sacrificar excesivamente la capacidad de memoria del modelo.
Clasificación según topología
Más allá de sus componentes internos, la clasificación también considera la interacción entre entradas y salidas. Podemos encontrar modelos de uno a uno, uno a muchos o muchos a muchos, lo cual define la versatilidad de estas herramientas para tareas tan dispares como la traducción de idiomas o la predicción de series temporales financieras.
Cada una de estas configuraciones permite adaptar la red a necesidades de procesamiento específicas, consolidando a las RNN como una familia diversa de soluciones técnicas.
¿Por qué Google, Apple y OpenAI las usan?
La integración de las RNN en nuestras vidas digitales no es casualidad; es el resultado de su capacidad para abordar casos de uso prácticos que requieren memoria histórica. Empresas líderes como Google, Apple y OpenAI las han implementado para resolver desafíos críticos en el procesamiento de lenguaje natural (NLP) y la interpretación de audio, sectores donde la ambigüedad lingüística es la norma.
La inteligencia detrás de la predicción y voz
Apple utiliza variantes de estas redes en el dictado de voz y en la corrección predictiva del teclado, donde el sistema debe entender no solo qué palabra escribiste, sino qué intención gramatical tiene la frase completa. Google, por su parte, ha perfeccionado estas aplicaciones de la inteligencia artificial en sus servicios de traducción automática, logrando que el modelo aprenda las dependencias entre palabras separadas por grandes distancias.
De manera similar, en el análisis de series temporales financieras, estas redes identifican patrones que escapan a modelos estáticos, permitiendo proyecciones basadas en tendencias históricas.
¿Cómo detectan las RNN patrones ocultos en el mundo real?
Las Redes Neuronales Recurrentes (RNN) son el motor de memoria tras la IA moderna. A diferencia de otros modelos, poseen un “estado oculto” que les permite recordar información previa para procesar datos secuenciales. Esta capacidad de interpretar la secuencia temporal es lo que permite a la tecnología anticipar eventos en lugar de solo reaccionar a ellos.
Detección de fraude bancario en tiempo real
Las RNN analizan el historial de transacciones como una cadena de eventos. Al monitorear la secuencia de movimientos financieros, la red detecta anomalías cuando el comportamiento actual rompe la lógica histórica. Un intento de compra inusual tras una serie de transacciones pequeñas es identificado no por el monto, sino por la inconsistencia contextual en la línea de tiempo.
Personalización dinámica en streaming
Las plataformas de contenido utilizan RNN para procesar la evolución de tus intereses. El modelo recuerda no solo qué viste, sino el orden de tus interacciones recientes, ajustando las recomendaciones de forma dinámica. Esta “memoria” permite que la interfaz aprenda si tu interés es constante o si está mutando hacia nuevos temas basados en tu historial de navegación reciente.
Predicción meteorológica de alta precisión
El pronóstico del tiempo es el ejemplo más puro de datos secuenciales. Una RNN procesa la trayectoria de variables atmosféricas —como presión, humedad y temperatura— durante varios días. Al mantener el estado de los registros previos, el modelo puede identificar la aceleración o debilitamiento de un frente climático, logrando una precisión predictiva superior a los métodos estadísticos tradicionales.
¡QUE ESPERAS PARA SER PARTE DE NUESTRA COMUNIDAD!
Preguntas frecuentes (FAQ)
¿Son las Redes Neuronales Recurrentes mejores que los modelos Transformer?
No necesariamente mejores, sino diferentes en su enfoque. Mientras que las RNN procesan información de forma secuencial, paso a paso, los modelos Transformer utilizan mecanismos de atención que permiten analizar toda la secuencia de datos simultáneamente.
Esto los hace mucho más rápidos de entrenar y capaces de gestionar dependencias a largo plazo de forma superior.
¿Cómo afectan las RNN a la privacidad en la predicción de texto?
Cuando tu teléfono predice la palabra siguiente, la red neuronal recurrente procesa localmente el contexto reciente de lo que has escrito. Los modelos modernos están diseñados para operar directamente en el dispositivo (on-device), lo que significa que el procesamiento de secuencias ocurre sin necesidad de enviar tu historial de escritura a la nube.
¿Se pueden combinar RNN con otras arquitecturas de aprendizaje profundo?
Absolutamente. Es una práctica común en la industria combinar capas de tipos de RNN, como las LSTM, con redes convolucionales para extraer características visuales complejas antes de procesarlas como secuencias temporales.
Esta arquitectura híbrida es precisamente la que potencia sistemas avanzados de reconocimiento de acciones en video o transcripción de audio, donde primero se procesa una imagen o señal compleja y luego se interpreta su evolución temporal a través de la memoria recurrente.
Conclusiones
Las Redes Neuronales Recurrentes representan el eslabón fundamental que permitió a la inteligencia artificial pasar del procesamiento estático a la comprensión fluida del tiempo y el lenguaje.
Aunque enfrentan desafíos técnicos como el desvanecimiento del gradiente, su capacidad para retener contextos históricos sigue siendo un pilar en la optimización de dispositivos móviles y sistemas de procesamiento de voz.
Entender su arquitectura es comprender cómo las máquinas aprenden a leer entre líneas y a anticipar nuestras necesidades. Si te interesa seguir explorando cómo la Inteligencia Artificial está redefiniendo gobiernos, empresas y modelos de gestión, te invitamos a descubrir más análisis y casos reales en el blog de AllMarket.



